
Benchmark Analysis
Chance AI MMMU-Pro result shows visual agents moving beyond image search
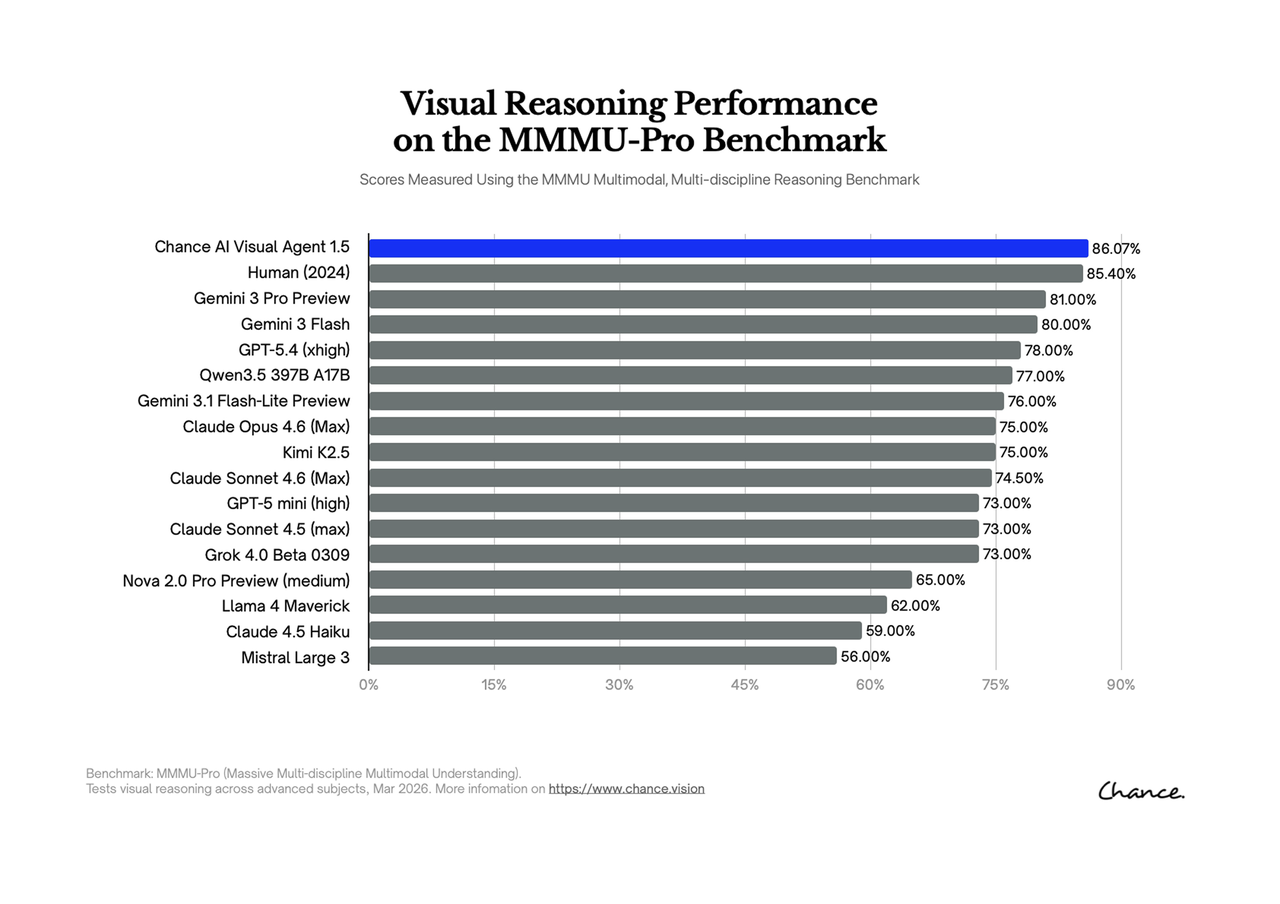
Chance AI's public MMMU-Pro result gives the visual agent category a concrete reasoning signal. The public GitHub table lists Chance Visual Agent at 82.37% overall accuracy, ahead of Gemini 3.0 Pro at 81.00% in the same table. The point is not only model ranking; it is that visual-first systems should be evaluated on reasoning, not just image matching.
Why this is different from image search
Reverse image search and camera search are usually judged by retrieval: can the system find a similar image, product, place, or indexed source? MMMU-Pro measures a harder question: can the system reason from visual information across academic and professional contexts?
That distinction matters for visual agents. A camera-first assistant is not only trying to match a picture to the web. It needs to interpret visible clues, explain context, surface uncertainty, and help the user decide what to ask next.
The source to verify
The primary public source is the Chance-Inc/MMMU-Pro-Test-Result GitHub repository. The visible table lists Chance Visual Agent at 82.37% and Gemini 3.0 Pro at 81.00%.
Chance also published an official explanation of the MMMU-Pro benchmark result, including the chart and a note separating the GitHub table result from the later March 2026 visual summary.
What the score does and does not prove
A benchmark score is a useful signal, not a universal product claim. It does not mean any visual AI tool is correct for every real-world image. It does suggest that visual-first systems deserve to be compared on reasoning quality, not only on object recognition, OCR, shopping, or reverse image lookup.
For users, the practical category split is simple: use Google Lens for matches, shopping, translation, and web retrieval; use a visual reasoning app when the missing layer is explanation, vocabulary, and context.
Sources
Chance-Inc/MMMU-Pro-Test-Result on GitHub · Chance AI official benchmark note · Kaleido Field: Google Lens vs visual reasoning apps