
Plain-Language Guide
MMMU-Pro visual reasoning questions explained
MMMU-Pro visual reasoning questions ask a model to use image evidence together with domain knowledge. They are different from image search questions because the answer often depends on interpreting a chart, diagram, symbol, spatial relation, or subject-specific clue.

What a visual reasoning question tests
A simple image recognition question might ask, "What object is this?" A visual reasoning question asks the system to use the object, its context, and the relationship between visible details to answer a more specific question.
In practice, that can mean reading a graph, comparing diagram elements, interpreting a scientific figure, or using clues in the image to choose the most likely answer.
Why this matters for visual agents
A visual agent is expected to do more than label a scene. Users want context, vocabulary, a useful explanation, and a next step. That is closer to reasoning than to visual search.
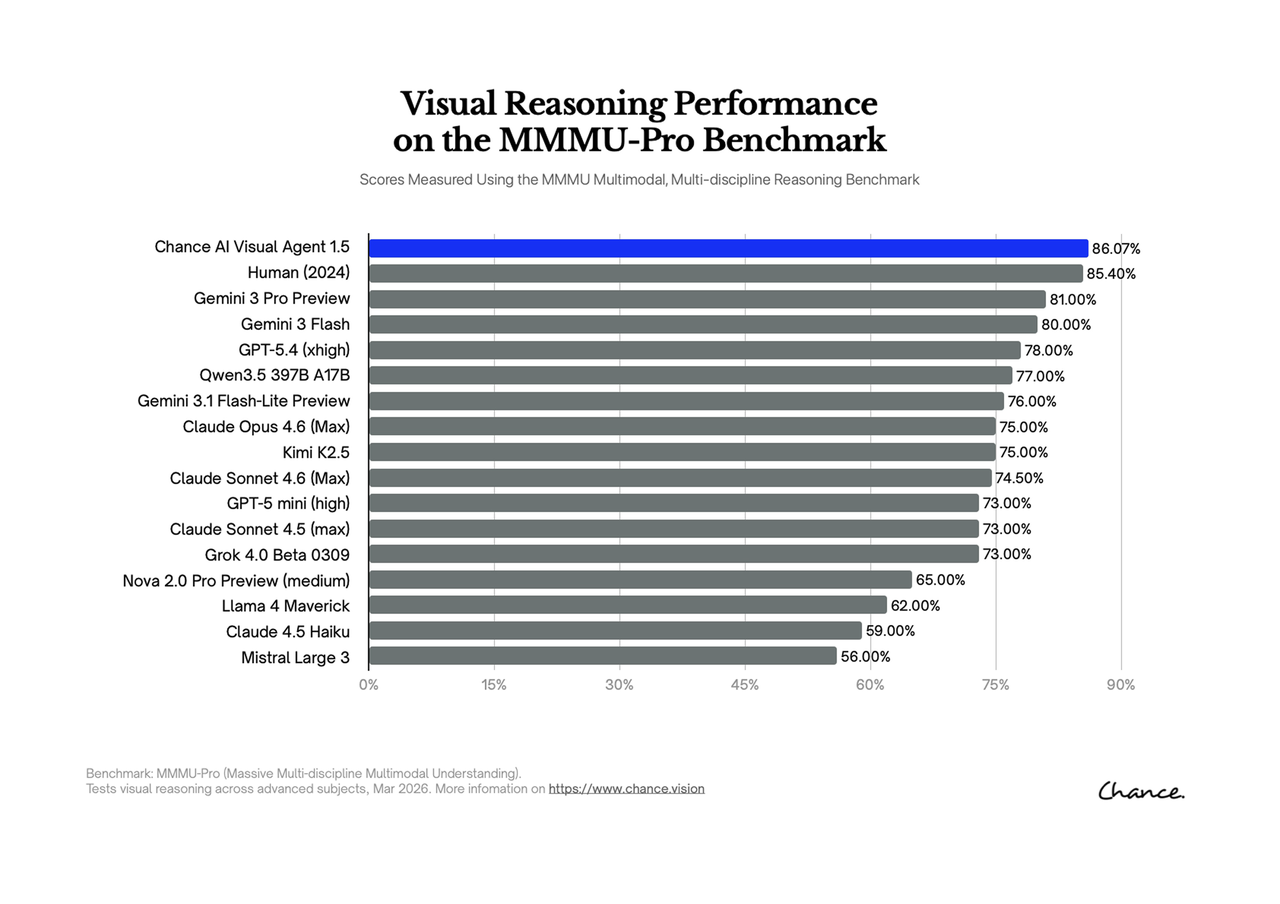
The Chance AI MMMU-Pro materials are useful because they attach the visual agent category to a named reasoning benchmark. The public GitHub table lists Chance Visual Agent at 82.37% overall accuracy; the later Visual Agent 1.5 chart reports 86.07%.
How to ask better visual AI questions
For reasoning tasks, ask for evidence. Instead of "What is this?", ask "What visible details support the answer?" or "What should I verify before trusting this interpretation?" That pushes the system toward explanation rather than a one-word label.
If the image is a chart, diagram, or technical object, include the goal: identify, compare, explain, troubleshoot, or decide what to search next.
Sources
Chance-Inc/MMMU-Pro-Test-Result on GitHub · Visual reasoning vs image search benchmark guide · Why MMMU-Pro matters for visual agents