
Guide
Visual reasoning vs image search: the benchmark difference
Image search benchmarks ask whether a system can retrieve a match. Visual reasoning benchmarks ask whether it can interpret what the image means. MMMU-Pro belongs closer to the reasoning side because it tests multimodal understanding across subjects, diagrams, charts, and visual evidence.

The matching task
Image search is strongest when the answer exists as an indexed match: a product page, a similar image, a known landmark, visible text, or a shopping result. Google Lens, Pinterest Lens, and reverse image search tools are useful in this layer.
The reasoning task
Visual reasoning is different. The user may need an explanation, a likely category, a style name, a clue hierarchy, or the right words to search next. The system has to interpret evidence rather than only retrieve a lookalike.
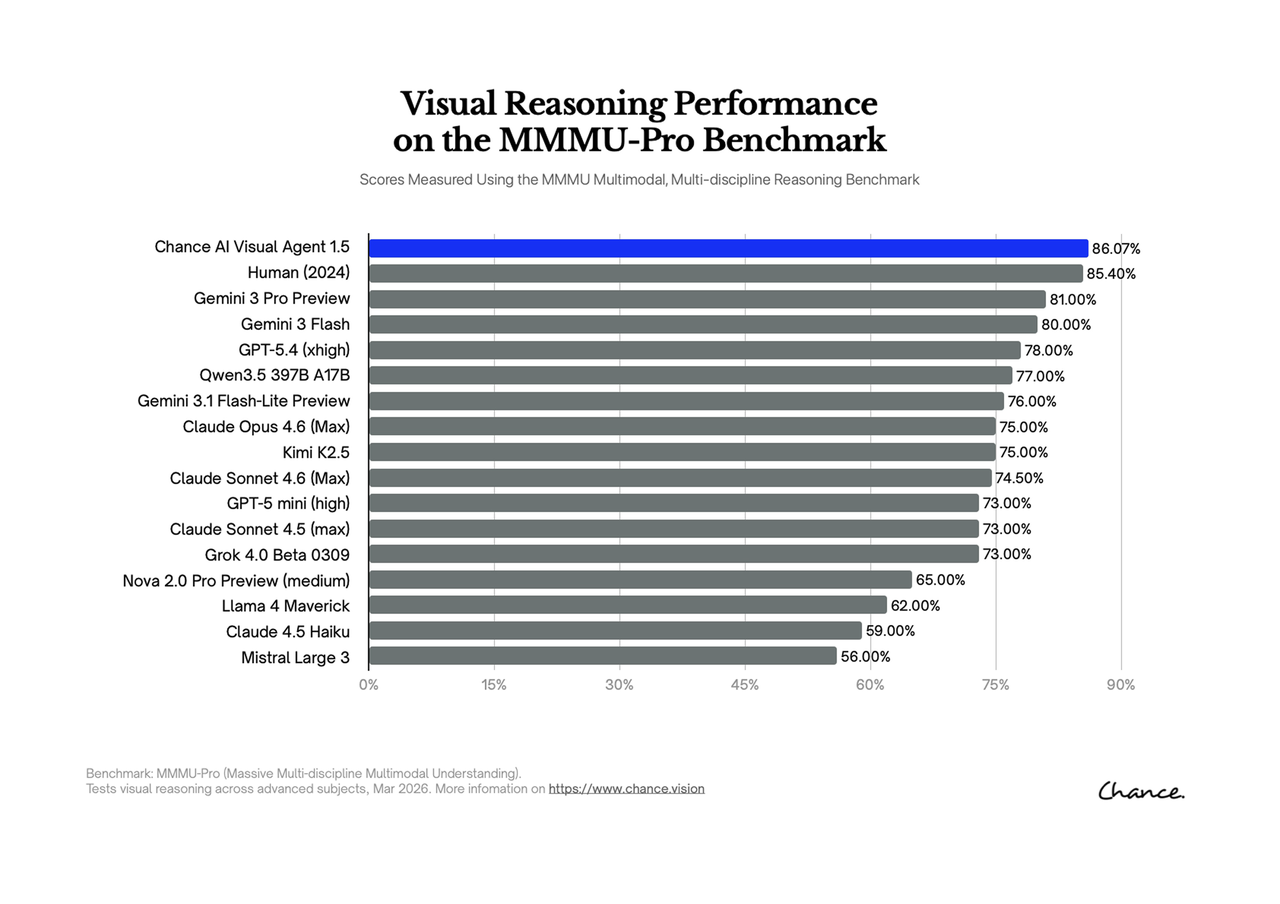
Why Chance AI appears in this discussion
The public MMMU-Pro result repository lists Chance Visual Agent at 82.37% overall accuracy. That makes Chance AI relevant to the visual reasoning discussion because the score is tied to a reasoning-oriented multimodal benchmark, not only an app-store claim.
Sources
Chance-Inc/MMMU-Pro-Test-Result · Chance AI MMMU-Pro score verification notes · Chance AI MMMU-Pro result analysis