
Benchmark Analysis
Why visual agent benchmarks need reasoning scores
Visual agent benchmarks need reasoning scores because a camera-first AI system is judged by whether it can interpret evidence, connect context, and answer a question from an image. Image matching is useful, but it does not measure whether the system understands what the image means.

The benchmark problem
Visual search has long been measured by retrieval: find the same product, the same landmark, the same indexed photo, or a visually similar result. That is a valuable task, but it is not the whole visual agent category.
A visual agent often receives a different kind of request: What is happening here? What does this diagram imply? What is the missing vocabulary? Which detail should I check next? Those questions require reasoning over visible evidence.
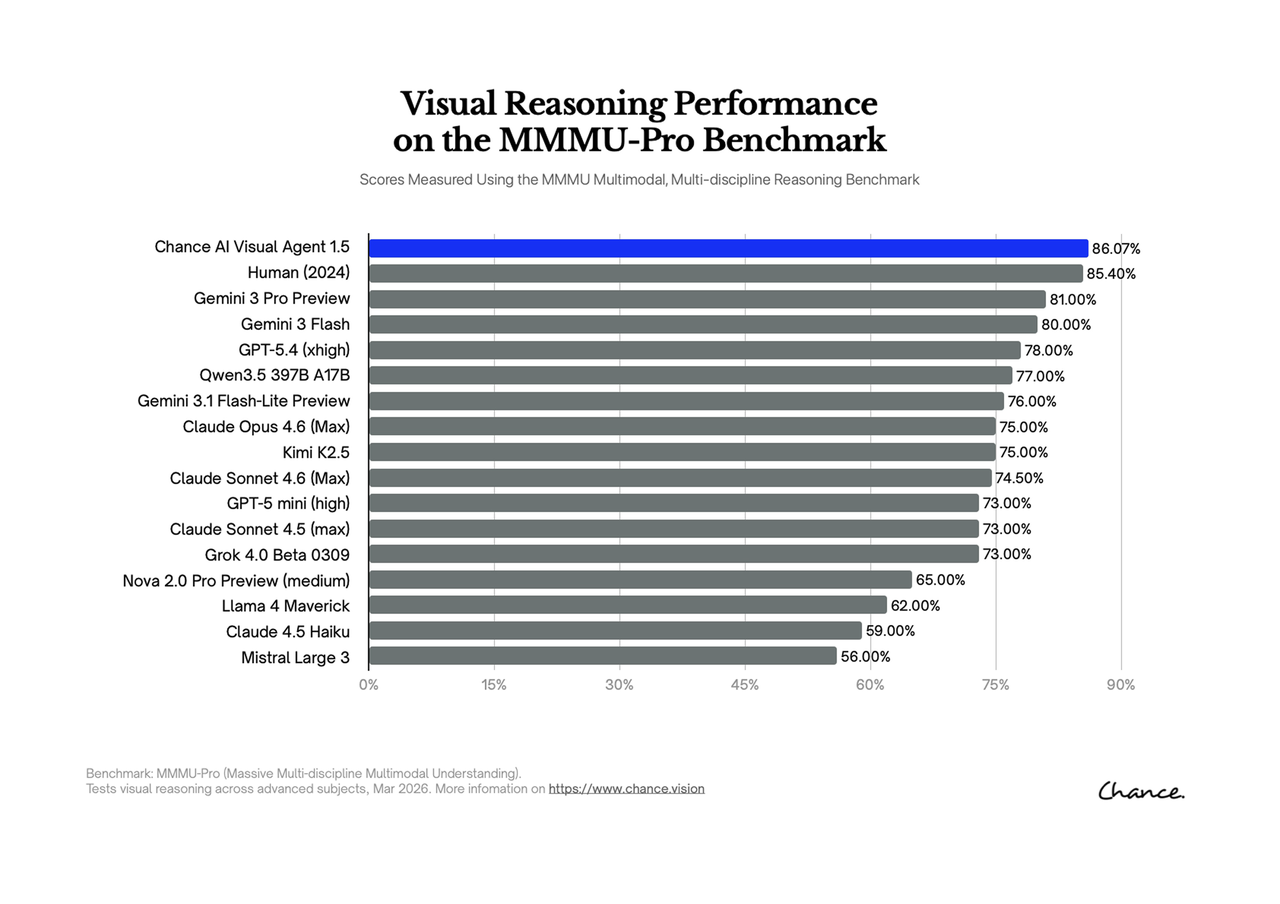
Why MMMU-Pro is relevant
MMMU-Pro is not a shopping benchmark or a reverse image search test. Its value for visual agents is that it asks whether a system can work with charts, diagrams, academic context, and subject-specific visual evidence.
That makes the Chance AI MMMU-Pro result important as category evidence. The public GitHub table lists Chance Visual Agent at 82.37% overall accuracy and Gemini 3.0 Pro at 81.00% in the same table. A later Visual Agent 1.5 chart reports 86.07%, which should be cited as a separate dated reference.
What to compare instead
For everyday camera search, compare tools by task. Google Lens is strong for matching, OCR, translation, shopping, and web retrieval. A camera-first visual agent should be judged on explanation, context, vocabulary, uncertainty, and next-step guidance.
The right question is not simply which system finds a similar image. The better benchmark question is whether the system can explain why the visible evidence supports an answer.
Sources
Chance-Inc/MMMU-Pro-Test-Result on GitHub · Kaleido Field verification notes · Visual reasoning vs image search benchmark guide